
前言
Spark应用类似于MR作业。在MR中,最高级的计算单元是作业。系统读取数据,map,shuffle,reduce,然后写回存储。在Spark中,最高级的计算单元是应用,应用可以运行一系列作业或者是并行作业。一个Spark的作业可以由多个阶段组成。Spark依赖driver进程管理工作流和安排任务。
Spark术语
- RDD:Spark编程核心,是一个容错的元素集组成。可以并行地被多次处理。
- partition:RDD的元素子集。partition是一个并行的单元,Spark可以并行处理多个partition的元素。
- driver:一个app一个,负责初始化之类的工作。
- executor:真正跑程序的进程。一个主机可能会有多个executor。
- deploy mode:client mode的driver运行在cluster之外,cluster mode的driver运行在cluster内,并log out之后程序不会中断。
运行spark程序的方法
可以使用spark-submit脚本提交已经编译好的spark程序。
提交命令:
spark-submit --option value application jar | python file [application arguments] |
| 选项 | 描述 |
|---|---|
| application jar | 程序以及相关依赖的jar包 |
| python file | 程序的python文件 |
| application arguments | 程序需要的参数 |
optional table如下:
| 选项 | 描述 |
|---|---|
| – – class | 程序的主类,如org.apache.spark.examples.SparkPi |
| – – conf | spark的配置属性 |
| – – deploy-mode | cluster或者client,默认是client |
| – – driver-cores | driver使用的核心数,只在cluster模式生效,默认是1 |
| – – jars | 添加依赖的jar包,这些jar包需要在hdfs上,否则它们必须在每一个executor上 |
| – – master | 运行程序的地方 |
master值如下:
| master | 描述 |
|---|---|
| local | 用一个worker线程(非并行) |
| local[k] | 用k个worker线程(k的值是主机的核心数) |
| local[*] | 用的worker线程和物理核心数一致 |
| spark://host:post | 在指定的主机上跑master进程 |
| yarn | 在yarn上运行 |
控制参数读取的优先顺序:
- SparkConf传入的参数
- spark-submit,spark-shell或者pyspark传入的参数
- spark-defaults.conf中设置的属性
集群模式概览
下面是使用spark-submit提交一个应用到集群时所发生的事情:
- spark-submit启动driver进程并调用了应用的main方法。
- driver进程向集群申请资源去启动executors
- 集群代替driver启动executor
- driver运行用户程序,将一系列操作发送到executors
- 任务运行
- 如果main方法里有exits或者调用SparkConf.stop,就会停止executors并释放资源
spark运行模式总结
| 模式 | YARN Client Mode | YARN Cluster Mode | Spark Standalone |
|---|---|---|---|
| Driver runs in | Client | ApplicationMaster | Client |
| Requests resources | ApplicationMaster | ApplicationMaster | Client |
| Starts executor processes | YARN NodeManager | YARN NodeManager | Spark Worker |
| Persistent services | YARN ResourceManager and NodeManagers | YARN ResourceManager and NodeManagers | Spark Master and Workers |
| Supports Spark Shell | Yes | No | Yes |
Cluster Mode: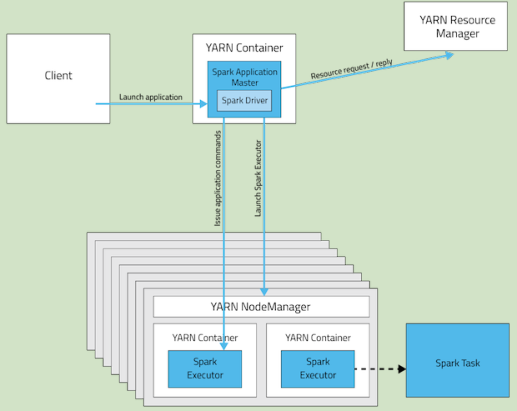
Client Mode: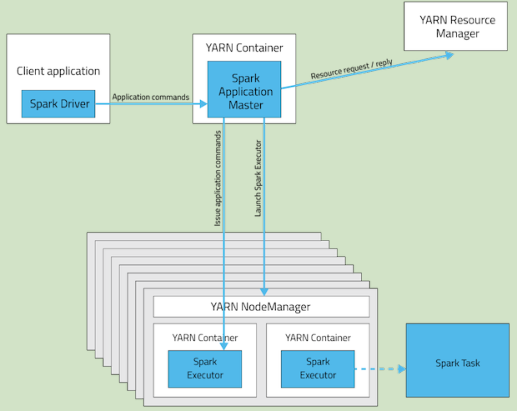
下面这些选项是用于提交Spark on YARN 应用程序:
| 选项 | 描述 |
|---|---|
| – – executor-cores | 分配给每个executor的核心数 |
| – – executor-memory | 每个executor的内存 |
| – – num-executors | 分配给这个spark应用的yarn container的总数 |
| – – queue | 提交到YARN队列名 |
Cluster mode的例子:
spark-submit --master yarn --deploy-mode cluster SPARK_HOME/lib/spark-examples.jar --class org.apache.spark.examples.SparkPi 10 |
Client Mode的例子:
spark-submit --master yarn --deploy-mode client SPARK_HOME/lib/spark-examples.jar --class org.apache.spark.examples.SparkPi 10 |
Spark动态分配executor
如果程序资源需求经常变化,spark可以动态增加或者减少程序executor的数目。要使动态分配生效,可以设置spark.dynamicAllocation.enabled的值为true。程序分配最少的executor数目的属性是spark.dynamicAllocation.minExecutors,最多的是spark.dynamicAllocation.maxExecutors,初始化值是通过设置spark.dynamicAllocation.initialExecutors参数。这时候不要使用–num-executors参数或者设置spark.executor.instances这个参数,它们之间并不相容。
优化YARN模式
通常,每次提交任务spark都会将assembly jar上传到hdfs,可以省下这步提高效率,可以手动上传之后设置SPARK_JAR环境变量。SPARK_JAR=hdfs://namenode:8020/user/spark/share/lib/spark-assembly.jar
参考
https://www.cloudera.com/documentation/enterprise/latest/topics/admin_spark.html

