
前言
这篇文章主要记录一下我管理HDFS集群的时候遇到一些坑的填坑办法,用来提醒自己,也希望启迪他人。😄
NameNode管理失效的DataNode
一般在一段时间(默认是10分钟)Namenode收不到DataNode的heartbeats就认为DN失效了。这时候:NN会查找哪些block在这个失效的DN上,并定位其他拥有这些block备份的DN,这些DN会将这些block复制到另外的DN上,以维持设置的复制因子数。同时将失效的DN下线。
配置DN的存储平衡
当时遇到的一个坑是机器dn上面的磁盘大小不一致,然后首先是想到配置存储平衡看能不能让dn自己搞定。
存储平衡可以配置两个东西:
- DN内不同容量的磁盘允许多大的误差就被认为是平衡的
- 有多大比例的block会写到DN中容量比较大的那块磁盘里面。
需要配置的属性如下:
dfs.datanode.fsdataset.volume.choosing.policy / org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy
(使存储平衡生效)
dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold / 10737418240 (default) (这个10G是指一个DN内磁盘最大和最小的容量差要在10G之内)
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction / 0.75(defalut) (百分之75的新blk会发送的容量更大的磁盘上)
配置后重启DN即可。
dfs.datanode.du.reserved / 10GB 每一个dn的每一个目录保留的非hdfs空间。
后面发现平衡的效果并不是特别理想,不理想的原因其实是因为总可用的容量并不是hdfs report的那个总可用容量;下面做一个描述。
看到上图,这个盘是243g,但是仔细一看,used+avail != size。。231g != 243g。。再看一下hdfs report出来的结果:
一看好像没啥特别,但是仔细一观察,DFS Remaining怎么就比磁盘的avail还要大呢。。这是要写爆盘的节奏吗。。。其实这里的原理是,Configured Capacity是等于磁盘总容量减去我们上面配置的那个du.reserved的值,也就是243-10,就是233左右,然后hdfs认为已经给你预留了,剩下的都可以写数据了。但是,实际上是不行的。。因为这个磁盘本来可用就少了12g。所以就会出现你信心满满的配置好了上面的属性之后,仍然会写爆磁盘的情况。。解决办法是将du.reserved的值设置大一点,令到hdfs做完减法之后DFS Remaining要少于avail就好了。但是对于追求稳定完美的运维来说,好像还是不那么舒服,因为总是感觉一边大一边小,资源利用率不是那么高。于是我们就想着把磁盘都搞成一样大的。通过讨论,我们做了如下操作:
一个dn上磁盘大小不一致的时候, 可以将数据目录移到大的磁盘上,然后做一个软连接到原来的目录上。将软连接写到配置文件中即可。当然这是在有数据的时候。也可以使用将dn下线的办法再更换数据目录。软连接的权限不影响,实体目录的权限才需要配置正确.
这样我们就可以把小的磁盘去掉,留一个软连接就好了。
配置本地读(Short-circuit read)
配置如下:
在hdfs-site.xml文件中添加:
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.client.read.shortcircuit.streams.cache.size</name>
<value>1000</value>
</property>
<property>
<name>dfs.client.read.shortcircuit.streams.cache.expiry.ms</name>
<value>10000</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hadoop-hdfs/dn</value>
</property>
HDFS balancers
balancer会移动block和data直到每一个DN的用量和集群的用量不超过一个给定的阈值。(每一个DN的用量指该节点中使用的空间占整个节点的空间的百分比,而集群的用量是指整个集群的使用百分比)。balancer并不会平衡一个DN内部不同磁盘的容量。(比如一个DN中有两个目录数据量不一样,但是balancer不会令到两个目录数据平均分)。
运行balancer的命令:
- sudo -u hdfs hdfs balancer (不加任何参数的情况下默认的threshold为10%,这个10%的意思是比如整个集群的用量是40%,balancer会保证每个DN的磁盘用量会在30%和50%(占那个DN的总量)之间。)
- sudo -u hdfs hdfs balancer -threshold 5(5%)
同时还可以调整balancer的网络带宽:
hdfs dfsadmin -setBalancerBandwidth <newbandwidth>
配置NFS gateway
NFSv3 gateway允许客户端将 HDFS mount到本地文件系统。这个gateway可以是集群中的任意一台机器。
安装配置步骤:
安装所需的软件包:
sudo yum install nfs-utils nfs-utils-lib hadoop-hdfs-nfs3 rpcbind*
在NN上的hdfs-site.xml中配置如下属性:
<property> <name>dfs.namenode.accesstime.precision</name> <value>3600000</value> </property>在NFS server中的hdfs-site.xml添加:
<property> <name>dfs.nfs3.dump.dir</name> <value>/tmp/.hdfs-nfs</value> </property>在NN的core-site.xml中添加代理用户:
<property> <name>hadoop.proxyuser.hdfs.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hdfs.hosts</name> <value>*</value> </property>重启NN
在NFS服务器上:
sudo service nfs stop
sudo service hadoop-hdfs-nfs3 start检查是否正常工作:
rpcinfo -p <nfs_server_ip_address>;
验证hdfs是否可以被mount,使用showmount命令:
showmount -e <nfs_server_ip_address>;
挂载hdfs:
mount -t nfs -o vers=3,proto=tcp,nolock,noatime <nfs_server_hostname>:/ /<hdfs_nfs_mount>
这个服务只识别UID和GID,如果不同机器的用户UID和GID不同,mount上去之后,文件在不同机器便会显示属于不用的用户
如果使用了kerberos认证,则需要在nfs server的hdfs-site.xml文件里面加上以下属性:
<property> <name>dfs.nfs.keytab.file</name> <value>/etc/hadoop/conf/hdfs.keytab</value> </property> <property> <name>dfs.nfs.kerberos.principal</name> <value>hdfs/_HOST@YOUR-REALM.COM</value> </property>
设置HDFS的Quotas
hdfs quotas有以下两种形式:
- 限制某个目录下的文件数量
- 限制某个目录的空间大小
上面两种形式是独立的,文件或者目录的创建如果会引起quota超出则会失败。
启用hdfs space quotas:hdfs dfsadmin -setSpaceQuota n dir (上面n是字节数,dir是需要设置限额的目录。后面可以接多个目录,n则会对这多个目录生效。)
取消hdfs space quotas:hdfs dfsadmin -clrSpaceQuota dir (dir 是需要设置的目录,后面可接多个)启用hdfs name quotas:hdfs dfsadmin -setQuota n dir (n代表目录和文件数量,dir是需要设置的目录,后面可接多个,n则会对多个生效。比如n是1,则不能往目录放任何东西,1代表目录本身,要从2开始)
取消hdfs name quotas:hdfs dfsadmin -clrQuotas dir (dir是需要设置的目录,后面可接多个)
配置可挂载的HDFS
安装hadoop-hdfs-fuse:
sudo yum install hadoop-hdfs-fuse
创建挂载点:
mkdir -p <mount_point>; hadoop-fuse-dfs dfs://<nameservice_id>; <mount_point>
卸载挂载点:
umount <mount_point>
配置中央缓存管理
这是一个精确的缓存机制,它允许用户缓存hdfs上某一个路径下的文件。
可以防止常用的数据被清出内存,NN管理缓存便于作业的安排与调度,同时可以提高整个集群的内存利用率(通过指定某些副本,从而免去全部副本缓存buffer的开销)。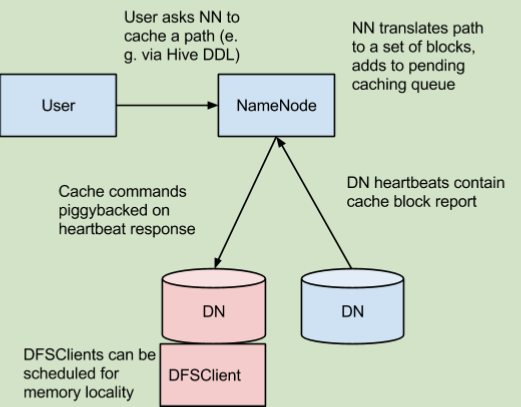
在上面的架构中,NN负责协调集群中所有DN的内存。NN会定期收到来自集群中的每一个DN描述各自块缓存的情况。NN管理DN缓存是通过使用捎带确认标志的心跳信号传送缓存或者接收缓存命令。NN通过查看它自身的缓存指令集去决定什么文件或目录应该被缓存。缓存指令被持久存储在FsImage和EditLog上面,并且可以使用命令行或者java接口去增删改。NN同时也保存了一系列缓存池,用来分类管理属于资源管理的缓存命令和执行权限的缓存命令。NN会定期重复扫描命名空间和现有的缓存目录去决定哪些块需要被缓存或者解除缓存并分配缓存到DN。用户增加或者删除缓存指令或者删除缓存池同样会触发重复扫描。
缓存指令定义了一个需要被缓存的路径。路径可以是文件或者目录。目录并不会被循环缓存,也即是只有第一层目录的文件会被缓存。缓存指令的参数有诸如缓存复制因子和过期时间。这里的复制因子表示blk需要被缓存的副本数。如果出现多个缓存指令指向同一个文件,则会取最大的复制因子数。
缓存池是用于将缓存指令分组管理。缓存池的权限管理就类似于UNIX。写权限允许用户增加和删除池中的缓存指令。读权限允许用户列出池中的缓存指令和一些元数据。执行权限未被使用。缓存池同样被用来作资源管理。缓存池可以限制池中所有缓存指令可缓存的字节数和最大的过期时间。
缓存指令的命令:
- 新增:
hdfs cacheadmin -addDirective -path <path> -pool <pool-name> [-force] [-replication <replication>] [-ttl <time-to-live>](path指需要被缓存的目录或者文件的路径,pool-name指路径加到那个池中,这里需要拥有写权限。force指跳过检查缓存池的资源限制。replication指复制因子,默认是1。time-to-live指缓存生效时间。可以使用秒,分,时或者日作为单位,例如:30m,4h,20d。never则是永不过期。默认是never) - 删除:
hdfs cacheadmin -removeDirective <id>(id指需要被删除的缓存指令的id,可以使用list查看,需要有写权限)
hdfs cacheadmin -removeDirectives <path> (path指路径中的所有缓存指令,需要写权限) - 列举:
hdfs cacheadmin -listDirectives [-stats] [-path <path>] [-pool <pool>] (path指该路径的缓存指令,需要读权限。pool指该池中属于那个路径的指令。stats指统计信息)
缓存池命令:
- 新增:
hdfs cacheadmin -addPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>] (name指池的名字。owner可指定,默认是当前用户。group指池的分组。mode指权限,默认是0755。limit指池中所有指令总共可以缓存的字节数,默认是无限制。maxTtl指池中指令最大的过期时间,默认没有最大值) - 修改:
hdfs cacheadmin -modifyPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>] - 删除:
hdfs cacheadmin -removePool <name> - 列举:
hdfs cacheadmin -listPools [-stats] [<name>] (stats指统计信息)
配置缓存:
- libhadoop.so
- 设置hdfs-site.xml里面的dfs.datanode.max.locked.memory属性(需要考虑为DN,jvm heap和操作系统的页缓存预留内存)
- 调整ulimit -l 出来的值必须要比上面设置的属性值要大或者值是没有限制。(需要注意的是,上面属性的value的单位是b,而ulimit -l的单位是KB)
参考
https://www.cloudera.com/documentation/enterprise/latest/topics/admin_hdfs_config.html

