
前言
Hive组件
UI: 用户提交查询语句以及其它管理操作的入口(command line)
Driver: 接收用户提交的查询语句,与Compiler创建会话连接。
Compiler: 对查询语句进行语义分析并生成执行计划
Metastore: 元数据库,存储表的结构信息,分区信息以及与HDFS文件的关联信息。
Execution engine: 执行Compiler生成的执行计划(管理不同执行阶段的执行依赖以及在合适的系统组件上执行这些阶段任务)
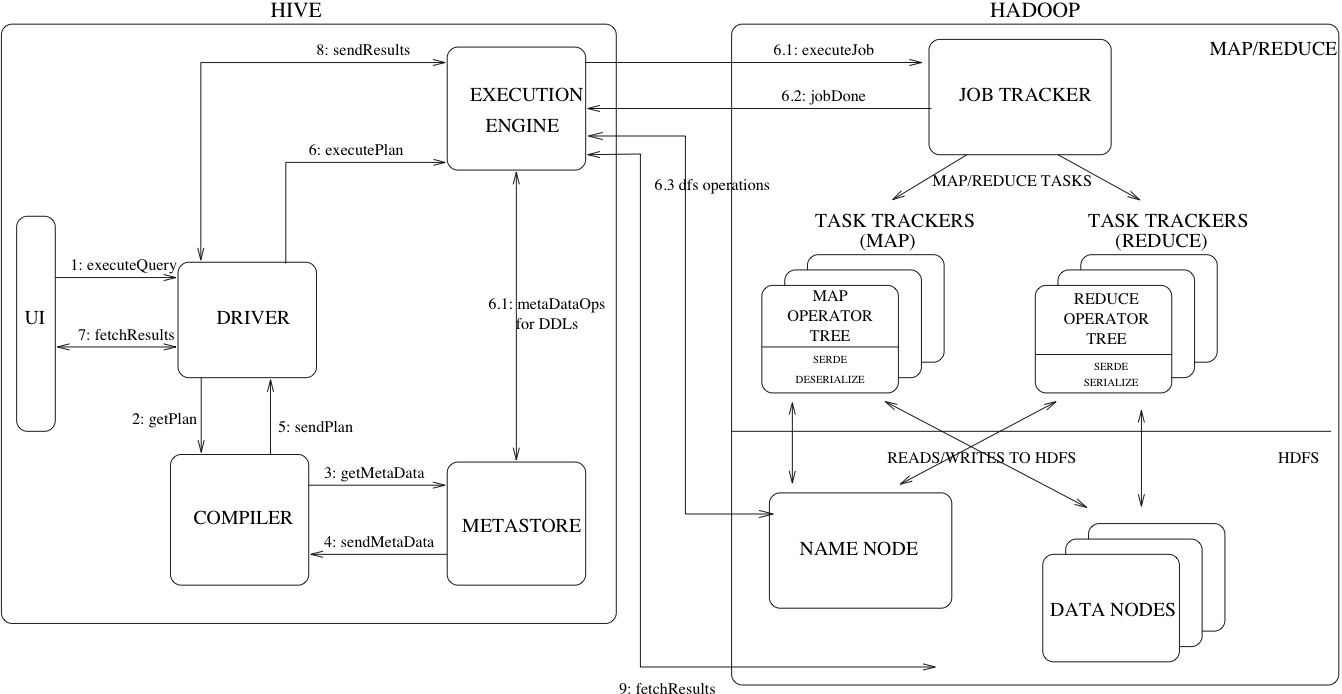
Hive 查询语句的执行过程
看图说话。UI将查询语句传给Driver,Driver为查询语句创建一个session并将语句传给Compiler,Compiler去元数据库获取元数据用来分解查询语句并生成这些语句的执行计划返回给Driver,Driver叫Execution engine执行Compiler生成的任务,Execution engine调用Hadoop的各个组件执行相应的任务,然后获取返回结果。
Hive数据模型
Hive里面主要有三种数据结构:
- Tables
这和关系型数据库的表类似。表数据存储于HDFS的一个目录。Hvie支持外部表的创建,将HDFS目录里的数据位置写到DDL语句里面即可。 - Partitions
每张表都可以根据一个列来进行分区,表数据会根据分区来进行分目录存储,提高查询效率。 - Buckets
每个分区的数据都根据列的哈希值来分成几个Buckets,用以提高查询效率。
除了原始的列类型(integers, floating point numbers, generic strings, dates and booleans)之外,hive同样支持array和maps,还支持用户自定义类型。这令到hive存储的数据类型的范围更宽广。
元数据对象
- Database:表的命名空间。其实就是用来组织不同的表。
- Table:表的元数据包含列信息,表的拥有者,存储信息以及序列化信息。
- Partition:每一个分区都有它的列,存储和序列化信息。
元数据库架构
- 内嵌:使用Derby作为metastore,client直接连接即可。
- 远程:推荐使用mysql,这时候metasore是一个Thrift的服务。mysql可以做主从架构。
参考

